Here’s an in-depth guide where we break down JsPDF, an open source solution that can help you quickly generate high quality PDFs from HTML.

JsPDF: What Is It & How To Use It To Generate PDF from HTML

It’s a PDF world, and we are just living in it.
The ask for this PDF format is universal. And today, we bring you a breakdown of an effective way to convert an HTML Document to a PDF and download it.
No. No! We aren’t talking about the Right-click > Save as PDF option.
This one is much more nuanced.
So let’s dive in!
First things first,
Where did this need to convert an HTML document to a PDF come from?
Most web-based projects or applications need report generation to show relevant data, including PDF conversion. In such cases, generating PDFs with different visibility rules specific to a particular user requires a flexible solution, such as JsPDF.
JSPDF is a JavaScript library that allows you to generate PDF files directly from your web pages. It is a powerful tool for web developers to create and generate PDFs on the fly, making it ideal for businesses, schools, and other organizations that require a way to produce professional and polished PDFs quickly and easily.
Riding on the back of an open-source library and the promise of flexibility, JSPDF allows you to generate PDFs from various sources, including HTML content, images, and even existing PDFs. Being an open-source library, it makes it free to use, modify and accommodate any specific need.
This makes it an ideal choice for developers who need a flexible and cost-effective solution for generating PDFs from their web applications.
Today, we will use jsPDF to download an HTML file as a PDF, images, colors & backgrounds.
PS: Stay tuned for the bonus section towards the end of the blog, which touches upon a presumably difficult use case killing two birds with one stone <PDF edition>.
Let us show you exactly how.
First, let’s set up some basic things to serve our images on the template we will build to implement jsPDF. We will be using AWS S3 Buckets for it.
Setting up an AWS Bucket
This bucket will hold our assets (preferably images) used in our HTML template.
Here we have our images ready to use now.
Configuring the Bucket to handle CORS
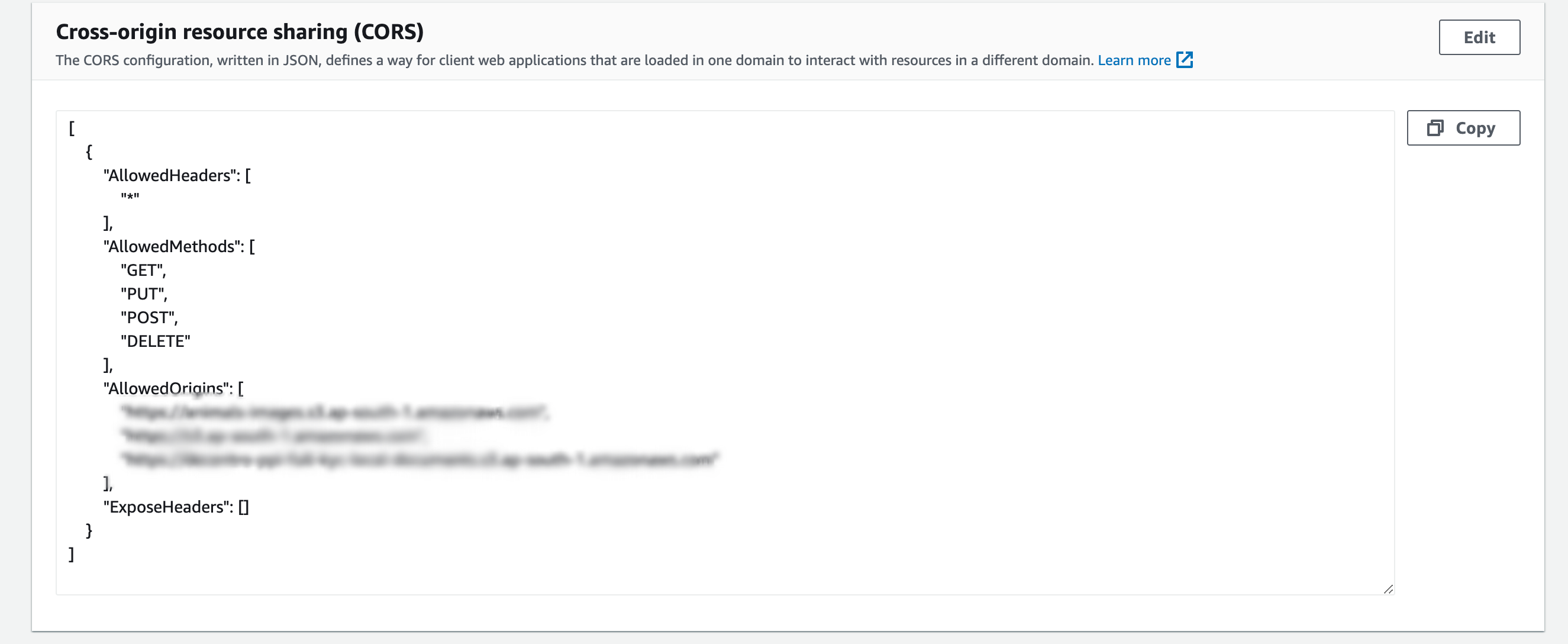
Wait! What just happened there?
Let me explain!
Since we at Decentro use AWS as our superpower, we have created an S3 Bucket and uploaded all the images we will use in our template.
Then under bucket permissions, we have dumped some CORS policy rules to allow cross-origin requests to our images in the bucket
Now onto setting up the template
HTML Template
We will build a basic HTML template with some sections holding data, background colors, a couple of images & a download button.
Use the code snippet below to build a basic HTML structure.
Output:
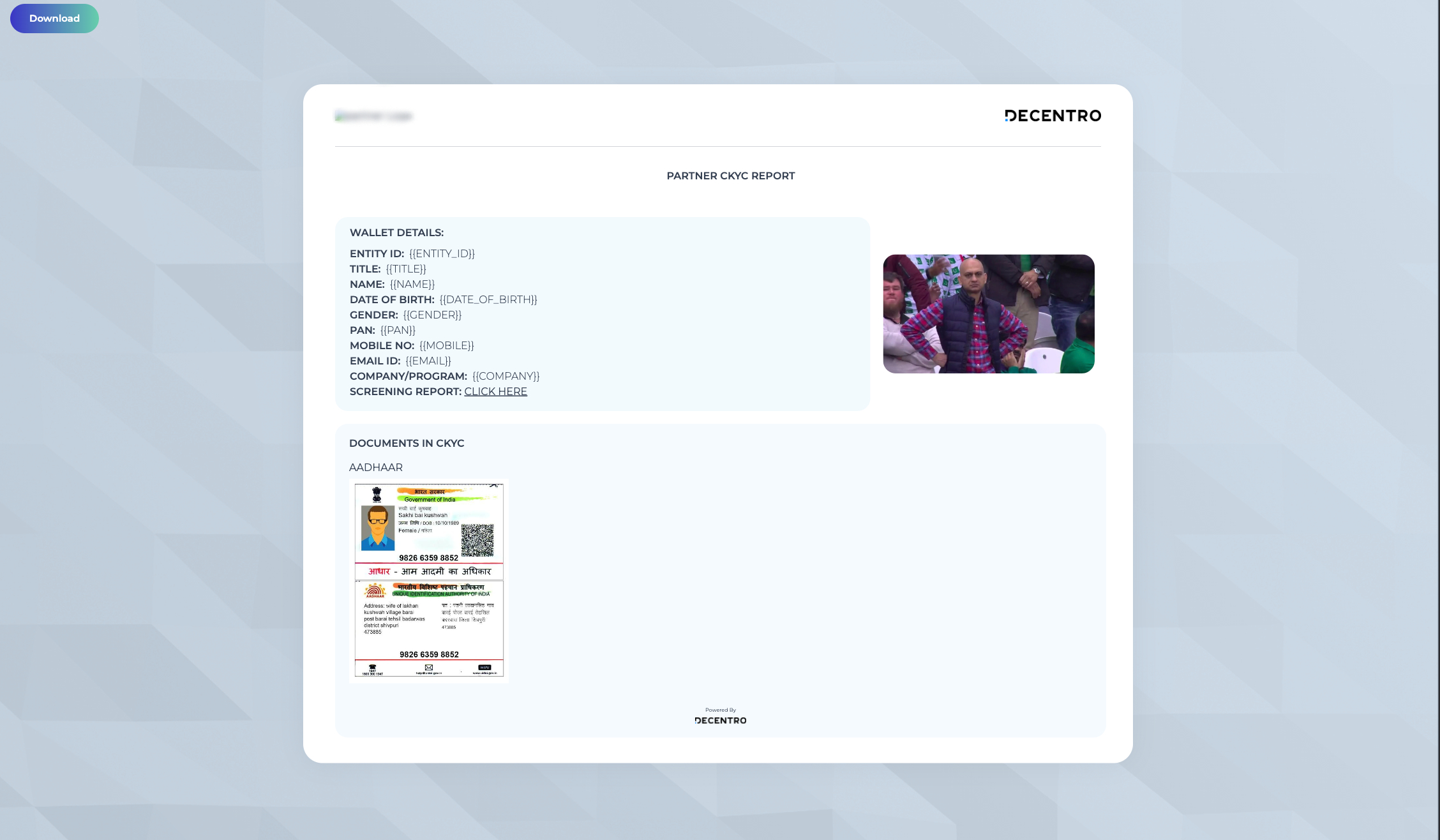
Above shown is the output of the template. Now comes the star of the show, jsPDF part
First, Set up jsPDF
To use jsPDF, you need to include the library in your HTML file. You can either download the library and include it locally, or you can include it directly from a CDN.
Here we will use the CDN to import the library, so let’s first add a couple of libraries at the head part of our template.
Then, we move on to attaching the onClick to Download Button
Now, Attach an onClick event with the Download button
The download button is linked with an onClick event which calls the downloadPDF function.
Finally, Download the HTML as a PDF
We will be creating a new jsPDF object. This can be done by calling the jsPDF constructor.
The constructor function of the jsPDF class takes an object as a parameter with the following three properties:
Orientation – Defines the orientation of the PDF document. In this case, it is set to “portrait” – ‘p’
Unit – Sets the unit of measurement for the document. It is set to points (“pt”) in this case.
Format – Sets the size of the document. It takes an array with two values: the width and height of the unit specified in the unit property. In this case, we have set it to a standard A4-size document.
Now, we will be adding content to the PDF object & try downloading the PDF
<Code here will be linked using Github Gist link – while editing the blog on wordpress>
The addHTML method of the PDF object is called, passing in the following parameters:
- $(“#mainContainer”) – a jQuery object representing the HTML element to be added to the PDF.
- 0 – the horizontal position (in millimeters) to place the element. In this case, it is positioned at the leftmost edge of the page.
- -20 – the vertical position (in millimeters) to place the element. In this case, it is shifted by 20 millimeters to accommodate margins or headers.
- { allowTaint: false, useCORS: true, page split: false } – an optional object containing settings for rendering the HTML element.
The allowTaint property controls whether to allow the browser to taint the canvas when rendering images.
The useCORS property controls whether to use CORS (Cross-Origin Resource Sharing) when rendering images.
The pagesplit property controls whether to split the PDF into multiple pages if the HTML element overflows the current page. - A callback function is executed after adding the HTML to the PDF. In this case, the save method of the PDF object is called to save the PDF file with the name {{downloaded_file_name}}.pdf.
Then, the “hidden” attribute of the HTML button with the ID “button-pdf” is removed to display the PDF download button.
Uploading the HTML file in the bucket

Created an S3 bucket again in AWS & uploaded the template in an object.
Copy the Object URL because this is where the template is rendered now.
Now as we open the link and HIT Download….
FINAL REVEAL IN 3..2….1
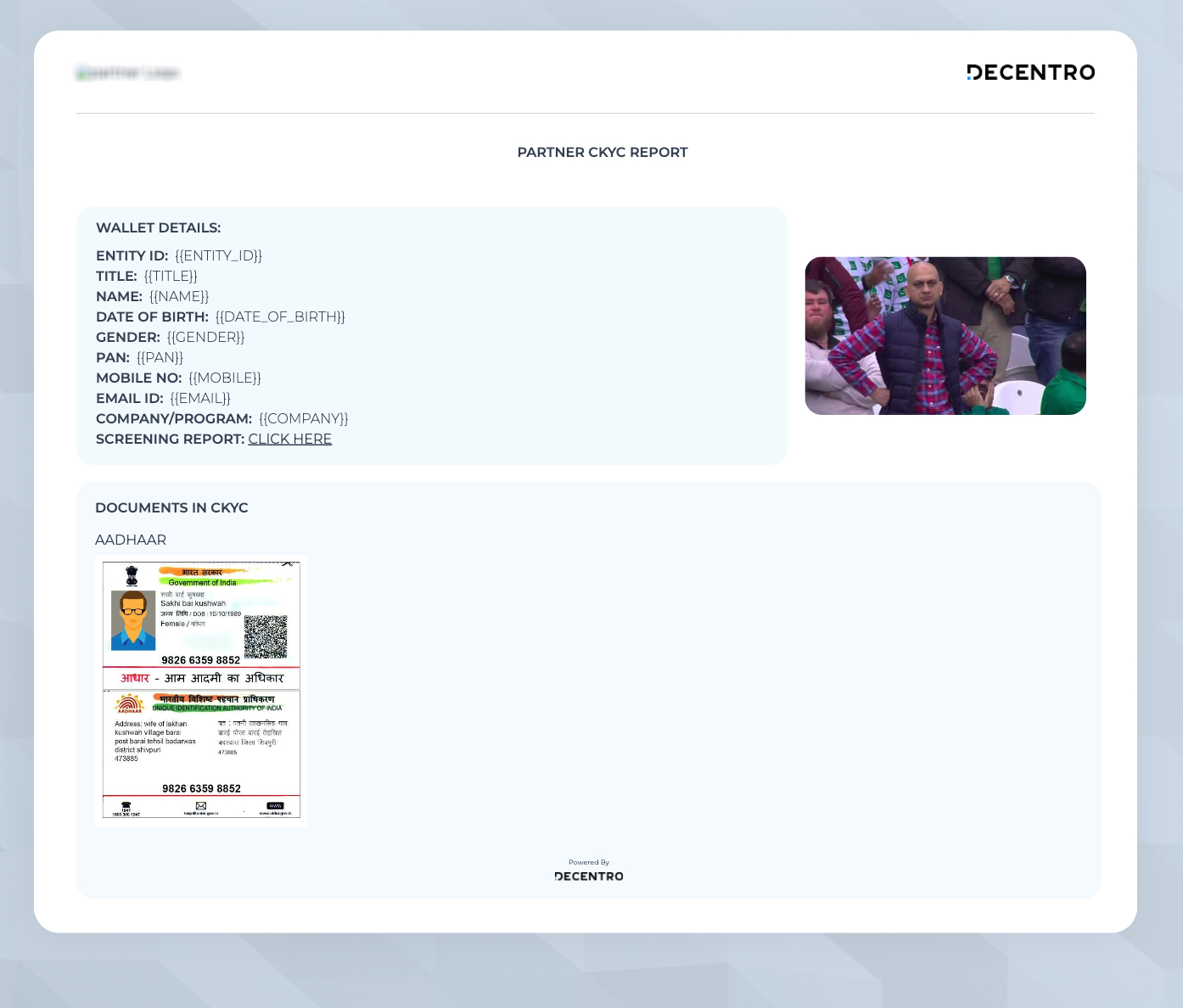
Picture-perfect PDF is what I like to call it.

Now for the BONUS CONTENT
Hold on! Hold on! We have got some BONUS content for you. As mentioned earlier, the idea here is to emulate the killing of two birds with the one-stone analogy. Let us show you how
Say I have a screening report link too in the template, which, when clicked, opens in a new tab and holds a screening report PDF.
The idea is to download both these reports simultaneously by clicking the download button once.
Can this be done?
Well, of course, YES!
To achieve this, let’s add more <CODE> to the existing one.
Now as we can see, If we click the link directly, it opens up in a new tab and displays a PDF file
Downloading both PDFs simultaneously
Let’s update our js code to the below code snippet to achieve both reports being downloaded on a single download button click
The downloadFile function downloads a PDF file from the specified URL using the fetch API and creates an anchor element with the download attribute to save the file.
Within the downloadFile function:
- fetch(url, { method: ‘get’, mode: ‘no-cors’, referrerPolicy: ‘no-referrer’ }) fetches the PDF file from the specified URL using the GET method and the “no-cors” mode.
- .then(res => res.blob()) converts the response to a Blob object.
- .then(res => {…}) creates an anchor element with the download attribute, sets the href attribute to the URL of the Blob object, and simulates a click on the anchor element to download the file.
- URL.revokeObjectURL(href) releases the Blob object URL.
That’s it; we have achieved what we set out to do: generate and download a PDF file using an HTML template.
So the ever-pertinent question must be addressed at the end of such deployments.
What’s next?
Since we can see the two PDFs, one being generated from HTML & one downloaded via an URL, are downloaded separately, we are now working towards downloading them in a single ZIP file as a wrapper to be shipped to customers.
More on that later.
Till then, feel free to indulge in the other works of the developers at Decentro, who are incessantly working on getting their subject matter expertise to you via these technical write-ups. Feel free to check out our blogs on multiple topics like NextJS, Jest, Metabase, and more.
That’s all with this blog. Until then, Keep snacking and keep learning!
Also, if you wish to connect with us, please drop us a line.

