Processing bulk payouts is a Herculean task? Nah-uh! Here’s all about how we solved it.

How We Deftly Processed Bulk Payouts With AWS + Pandas + FTP + Linux
Passionate about handsome system designs. Senior Engineer at Decentro combating the challenging aspects of Finance and Tech.
Table of Contents

“The simplest solution is always the best” – William of Ockham
This quote embodies the essence of making beautiful designs for me; let this quote remain with you throughout your read.
If you are reading this, you probably have a rough idea about Decentro. For the unfamiliar folks, we are an API Banking platform that acts as a middleman between applications and providers such as banks.
An important service we provide is payouts, i.e., transferring money out of (hence called PAY – OUTS) one’s virtual account to a physical account. We have dedicated APIs to make this happen.
All Was Going Well Until…
Our customers were in need of a mechanism to make thousands of payouts in a single shot instead of individual requests for each transaction. We rolled up our sleeves, hopped on a call with our provider bank to see how we could feasibly achieve this, and got ready to work!
The solution we came up with was to use… (wait for it!)

How Did We Set Up APIs for Bulk Payouts?
We decided to collect the data from our clients in a CSV file instead of our regular APIs. For the same, we used our dashboard to maintain the user experience, similar to corporations crediting salaries to hundreds of employees in one shot on their bank’s portal.

Why a CSV(comma-separated values) File?
Simply because it can be easily created using modern excel tools, and they are a piece of cake to parse in most modern languages, including Python, which we use as our primary language.
So, the administrator of a particular client signs in to their dashboard to find the Bulk Transfer button.
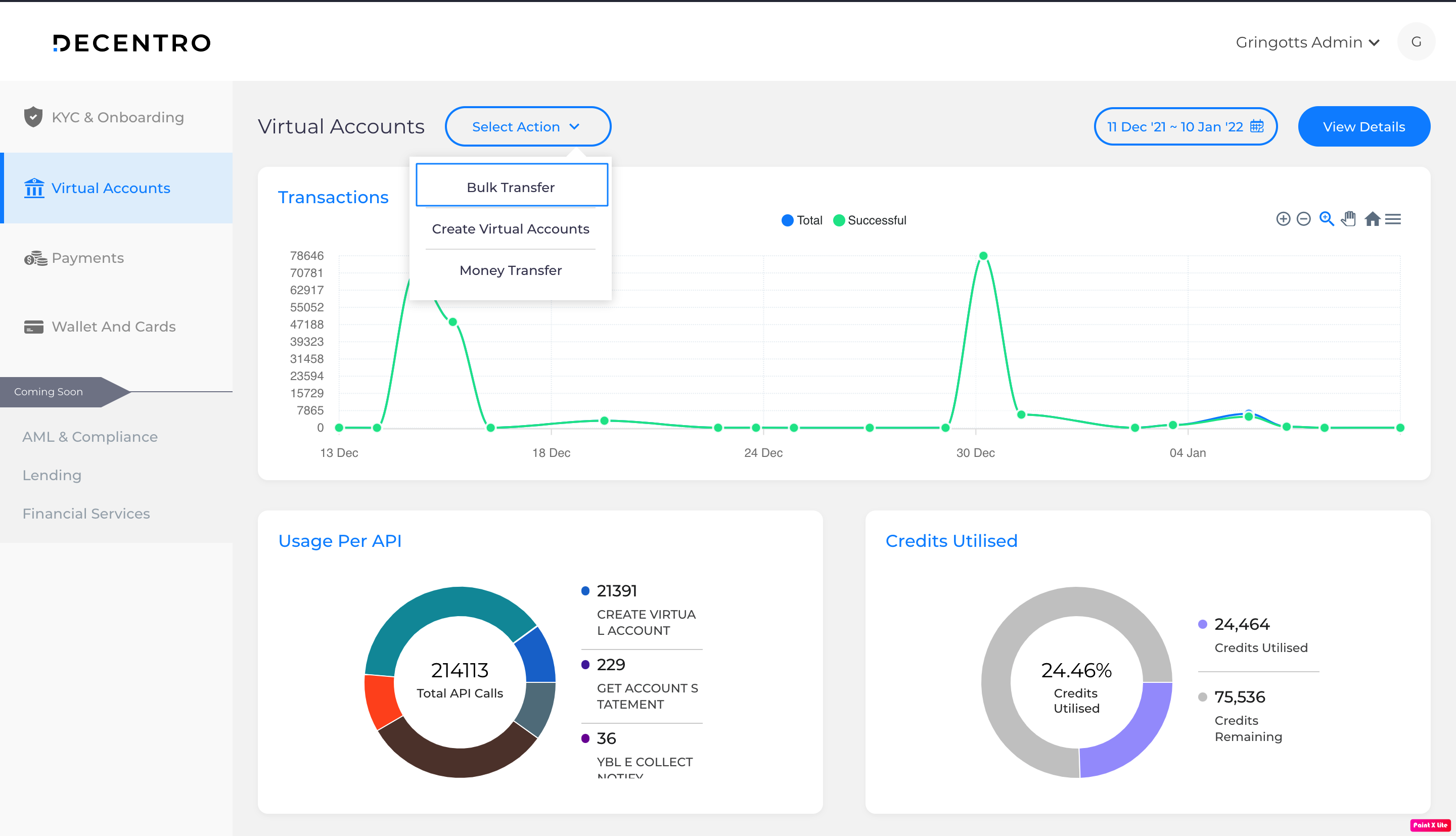
A form opens up with four mandatory fields:
- Virtual Account(VA) number of the remitter
- IFSC Code associated with the VA
- File to be uploaded
- Provider Bank
A sample file is available for download on this screen with the following column headers:
| Transfer Method* | Unique Customer Ref No* | Name of Beneficiary* | Amount* | Beneficiary Account No.* | Beneficiary IFSC Code* | Beneficiary Mailing Address* | Debit Narration | Email ID |
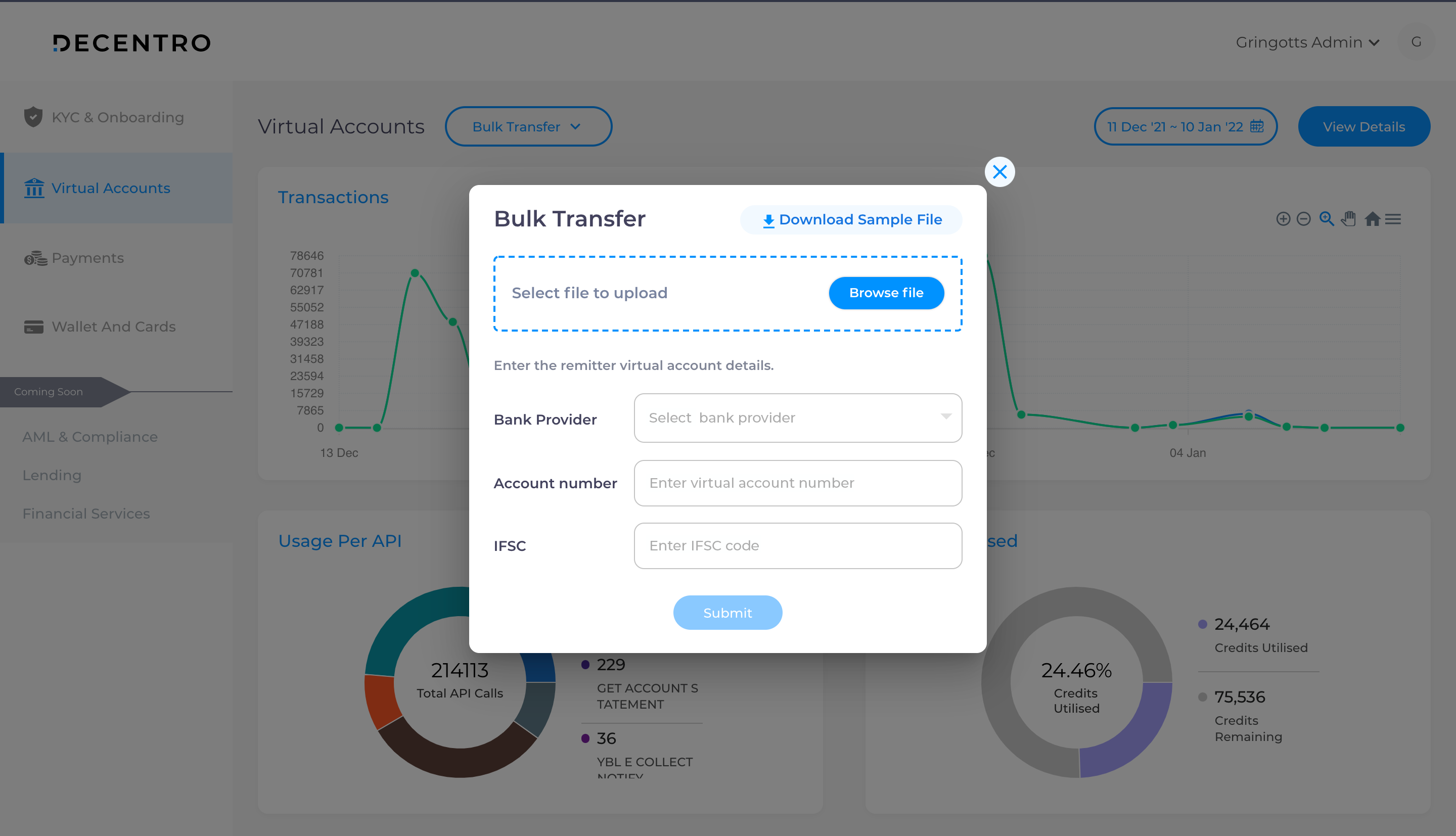
Upload File API
Once the form is submitted, our first API is called, which will accept the file. It is responsible for carrying out validations. We parse it using an internal python module called csv. Further, we extract the headers and validate them along with each row of data by iterating through all the records.
How Did We Perform Sanitization Check on the File?
We wanted to make the file sanitization utility a generic one to save time writing the utility again. Therefore, we created a JSON that had details of each column’s constraints and a utility that could iterate through the values in the row against the constraints mentioned in the config.
A Bad Request would be thrown whenever a condition is violated, along with an appropriate response message of the failure. For every file sanitization requirement in the future, we will simply have to add a JSON in the config defining the constraints and let the utility take care of the rest.
Our API stack runs on a commission revenue model.
In the case of payout via API, there is just one transaction; therefore, it is simpler to charge a commission, unlike bulk payouts where each row would need to have its commission calculated (depending on the amount & transaction method – NEFT/RTGS/IMPS) and charged.
Since iterating through thousands of records is a costly affair, we make use of the iteration above to calculate the commission and insert the commission value in a column we introduced programmatically called decentro_commission for all the transaction rows.
With this process complete, we now have a sanitized file with the commission values of each transaction. We directly upload the file to Amazon’s Simple Storage Service, also known as AWS S3, to be accessed later.
Why AWS S3?
It is a cheap, scalable, high-speed cloud storage service that supports AWS’s huge infrastructure and presence of AWS SDK for Python, known as boto3, making integration with any AWS service a walk in the park.
Finally, the API sends an OTP via SMS to the registered mobile number utilizing Amazon’s Simple Notification Service and returns a response to the dashboard that consists of Decentro’s transaction ID.
OTP Verification API
The previous API dealt only with sanitization; this is where things start to get serious, as a few banking operations are undertaken. This API accepts OTP in JSON along with the Decentro’s Transaction ID in the URL. After the OTP is verified, we fetch the file from S3 that was uploaded in the previous API and use Pandas to read the file.
P.S. Don’t worry, WWF didn’t mind as we used the library and not the endangered species.

What is Pandas?
Pandas is a fast, powerful, flexible, easy-to-use, open-source data analysis and manipulation tool, built on top of the Python programming language. In our case, it reads the file and returns a data frame that can be used to retrieve useful information about the data present in the file.
- Without directly iterating the file, we get the sum of transfer amount as well as the total commission to be charged using Pandas.
- Now, similar to a bank, we will verify if the total transfer amount is present in the VA (given in the first API) as well as check the balance in the commission debit account against the total commission.
- With this verification out of the way, we push the request (known as message in AWS ecosystem) into a dedicated queue which is primarily Amazon’s Simple Queue Service or AWS SQS.

Bulk Payouts Poller
Up to this point we were writing everything on Decentro’s main application which took care of sanitization and financial verification. However, we did not want to make the real money transfer process a synchronous one, especially not in the main application.
Writing the poller independent of the main application has numerous benefits:
- First and foremost this gives us the flexibility to run the poller on a separate server having its own physical specifications
- The performance of our regular APIs would not be influenced
- Any changes to the poller would not require any deployment of the main application.
The poller keeps polling the queue looking for new messages. Once it gets a message, we extract relevant details and fetch the file from S3. Once again we make use of pandas to get the total transfer amount as well as the total commission amount.
Now, we get to a tricky part. There are two ways to proceed:
- We can insert each transaction in our database and keep debiting money from the VA simultaneously – this is how our regular payout API works
- We can pre-debit the balance all at once and bulk insert records directly to DB

We chose the second option because connecting to DB thousands of times for the insert is a bad idea, is not scalable, and would increase the load on our main DB, ultimately affecting the performance of regular APIs.
But, the risk here is we pre-debit the total amount, which means there would be no record of the transactions for a few moments, yet there would be a reduced balance. So, if there is a failure while inserting, we have debited the amount but not recorded the transaction.
We have to live with this flaw, and the best way to handle this is to absolutely make sure nothing breaks between debit and inserting the records. For the second time, we will be iterating through the file (imagine how expensive this would be on the main application or doing it synchronously), generating insert strings for each transaction, and keep adding the transactions to a new file in the format the bank expects them.
If the company is on the Pay As You Go plan, we will also generate commission records’ insert statements. Wait! There is a catch- Each commission record is mapped to its parent transaction, which we won’t have unless we bulk insert all the main transaction records.
- So, we generate a reference number for each transaction and map insert statements of the commission records with the reference number associated with its parent transaction.
- After bulk inserting the transactions, we fetch all the records querying on the reference numbers and update the commission record strings with the primary key value of individual transactions associated with the same reference number.
- Now we have the commission transfer records with the mapping with its parent transaction, and we bulk-insert them as well.
We push the bank readable file to S3 for our records and then to a dedicated Snorkel server for H2H communication via FTP using pysftp package.
H2H Snorkel Server
The file is received by a dedicated server that communicates with our provider bank using a Host-to-Host automated system primarily used for high volume data transfer between banks and their corporate clients. The provider software keeps polling for any new file in the specified directory, it uploads the file to its own host for further processing and leaves an acknowledgment with the details of the file uploaded.

After the provider has processed these transactions, it returns a few files with details of the transaction.
If all details of a particular transaction are correct (like account number, IFSC code, etc.), it is successful; otherwise, the transaction is rejected, and the reason for the same is also mentioned. We have implemented Linux’s inotify API in the directory where the response files are dropped.
Why inotify?
The inotify API provides a mechanism for monitoring filesystem events. It can be used to monitor individual files or to monitor directories.
In this case, we use it to trigger a script whenever a file is created -> written -> saved in the specified directory. Moreover, inotify also gives us the filename where these actions were performed.
The script retrieves each row from the provider-generated file and makes an internal notify call to our main application to update each transaction’s status. If any transaction fails, it is marked as failed in our system with the appropriate message given by the provider, and the commission is refunded.
After all the records of particular bulk payouts have received a response from the provider it is marked with:
- Failure – In case of all transactions failing or any issue throughout the flow
- Partially Success – If some of the transactions were successful
- Success – If all transactions were successful
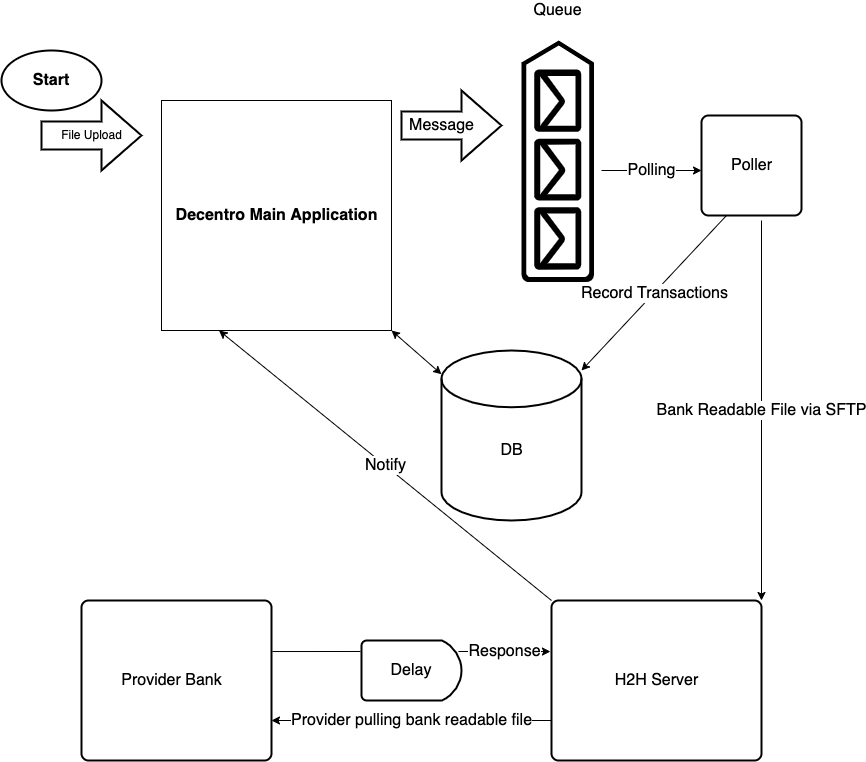
And, that’s the end of how we process a huge number of payouts in a file.
Flaws & Things To Improve
- The most prominent flaw that I find is the requirement to iterate the file twice. It is an expensive process, and we wish we could do away with it. However, we need one iteration to make a sanity check on the values as well as calculate the commission and the other one where the magic happens.
- Another flaw is not debiting the money in the second API, where we check for the balances. This, of course, leads to a chance of withdrawal after the transaction is pushed to the queue, although we check the balance again before debiting, and it would fail the transaction if the balance check fails in any of the places. This had to be done because we did not want to debit the money in synchronous flow as there could be a delay for the poller to pick up the message. This, in turn, would result in no records of the transactions existing but a balance reduction for the client. Consequently, this would generate an erroneous statement.
- Having the poller independent of the main application means we had to write almost all the infrastructure level code from scratch, which would not have been the case if the flow was synchronous. In any case, we are happy to make this sacrifice over having the poller affect the performance of our main application.
Possible Enhancements
- Further down the line, we can make use of multithreading to read the records of the files since no two records have any dependency on each other.
- Amazon’s Batch service can fit in perfectly here to reduce the load on our system for a fee.
Wrapping Things Up
No system is perfect, and no system can be above improvements; we have to best use the design to work with the core product and bring the best customer experience out of it.
We started off with APIs to authenticate the client and verify the file. Then moved to the asynchronous flow to record the transaction, uploaded the file to the H2H server where the provider picked it up and returned the response file, which was read by a script, and records were updated to their respective statuses.
And, that’s it, that is how we processed bulk payouts with the objective “The simplest solution is always the best.”
In case it spikes your interest, our engineering team at Decentro has penned more tech blogs to satisfy the developer within you. Be it why we moved to Kong API Gateway from NGINX, or a pocket guide on API Request Validation.
We’ll see you next time with yet another tech story!

