Dive into how Decentro uses Celery to boost background tasks and efficiency in API development. Simplify your workflow and elevate your development projects with this guide.

Understanding Celery: Simplifying Background Tasks in Python
CTO at Decentro. Making fintech great again!
Table of Contents

API development is primarily done for real-time or near-real-time responses from systems, but what do you do when a large dataset takes time to prepare or when a task depends on sending an email?
Enter our saviour – CELERY
Although it’s a green vegetable that is good for health, in Python’s case, it’s an even better tool for your system’s health.
What is Celery?
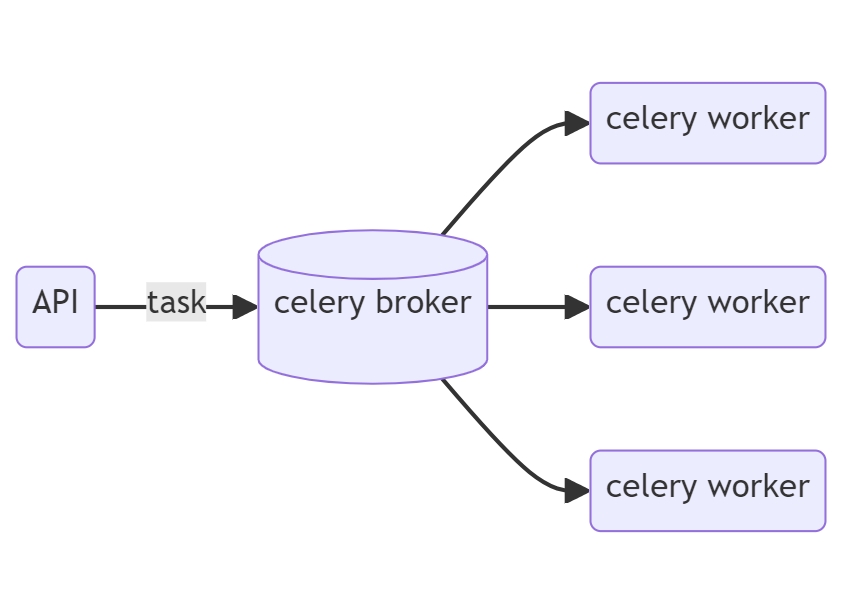
Celery is a tool to maintain task queues based on distributed messaging systems.
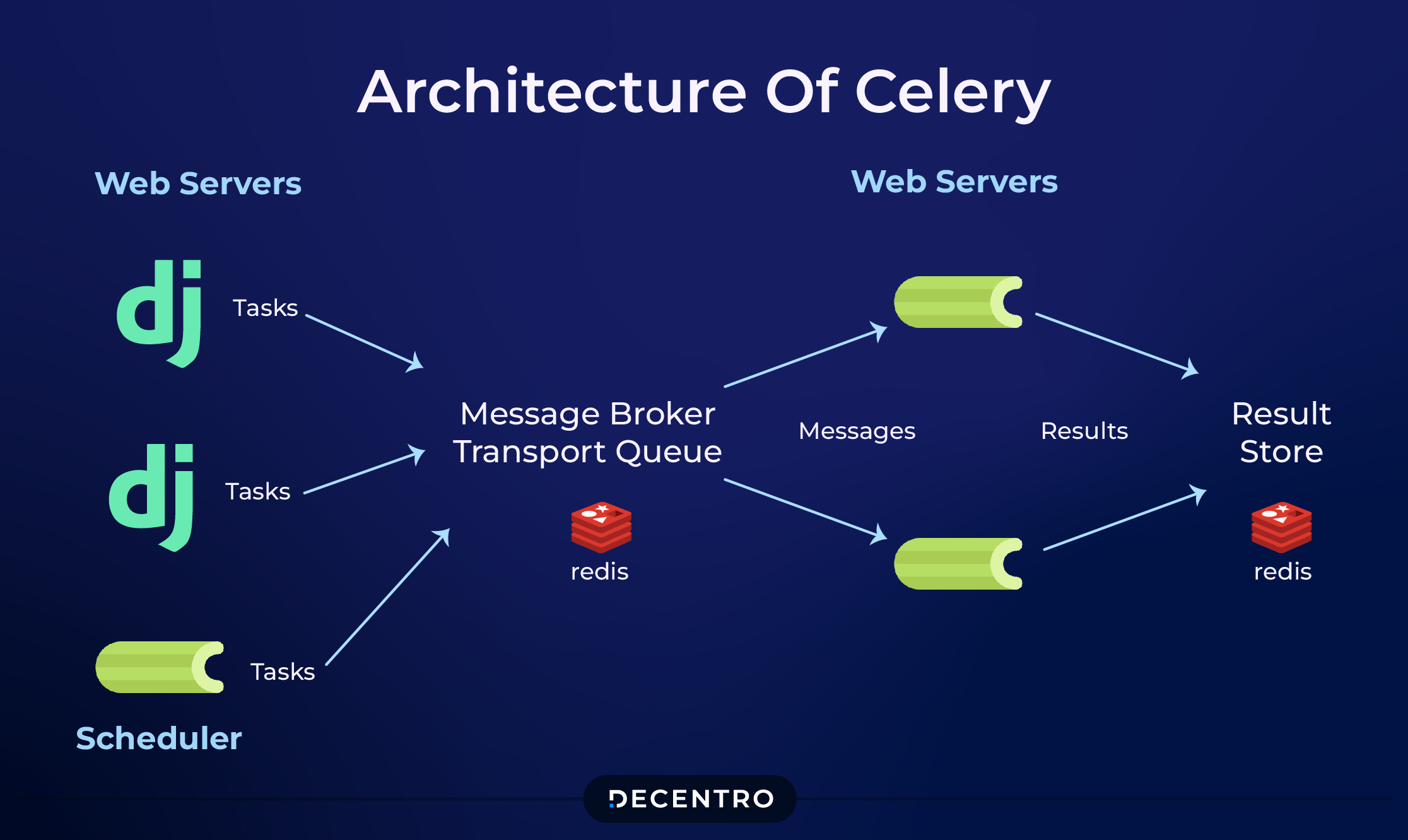
Task queue, as the name suggests, is a way of storing tasks which will be picked up by workers who will complete these tasks
Distributed messaging systems manage messages so that the producer (python script/API) and consumer (celery worker processes) can communicate with each other. Examples of such messaging systems are RabbitMQ, Redis, and AWS SQS.
So, in a nutshell, Celery acts as a middleman between producer and consumer in managing the tasks.
Use Cases
Since it is slightly complicated to work with celery, why should I use it?
I am going to break down this blog into 3 use cases:
- Large dataset
- Run multiple tasks
- Background validation of data
Get your coffee ready; we are starting with a problem many of us have faced.

Large Dataset
Our organisation relies heavily on data. Sometimes, extracting this data from our database using queries might take a few minutes. We do not want our users (internal or external) to wait for responses in real-time.
Our users are happy to receive the extracted dataset through an asynchronous process, such as email or Slack.
Celery to the rescue!!
We can use Celery to create tasks that the workers can pick up asynchronously and process as background tasks.
Steps to make this:
- Create a restful API using any Python framework like Flask, Django or any other.
from flask import Flask, jsonify, request
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///users.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
Base = declarative_base()
# Define the User model
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
# Create the database engine and session
engine = create_engine(app.config['SQLALCHEMY_DATABASE_URI'])
Session = sessionmaker(bind=engine)
# Function to fetch users from the database
def fetch_users():
session = Session()
users = session.query(User).all()
session.close()
return [{'id': user.id, 'name': user.name} for user in users]
# Endpoint to get all users
@app.route('/users', methods=['GET'])
def get_users():
# Call the function fetch users from the database
task = fetch_users()
# Return a task ID to track the progress
return jsonify({"task_id": task.id}), 202
if __name__ == '__main__':
# Create the database tables if they don't exist
Base.metadata.create_all(engine)
app.run(debug=True)
- All the users’ lists are fetched in the above example as a real-time operation. We will change this by adding celery to process users asynchronously. We will request to hit the fetch_users function, but it will not return the results. It will instead provide us with a task id which can later be used to obtain the results of that task using /users/<task_id> endpoint.
from flask import Flask, jsonify, request
from celery import Celery
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
app = Flask(__name__)
app.config['CELERY_BROKER_URL'] = 'redis://localhost:6379/0'
app.config['CELERY_RESULT_BACKEND'] = 'redis://localhost:6379/0'
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///users.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
celery = Celery(app.name, broker=app.config['CELERY_BROKER_URL'])
celery.conf.update(app.config)
Base = declarative_base()
# Define the User model
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
# Create the database engine and session
engine = create_engine(app.config['SQLALCHEMY_DATABASE_URI'])
Session = sessionmaker(bind=engine)
# Celery task to fetch users from the database
@celery.task
def fetch_users():
session = Session()
users = session.query(User).all()
session.close()
return [{'id': user.id, 'name': user.name} for user in users]
# Endpoint to get all users
@app.route('/users', methods=['GET'])
def get_users():
# Call the Celery task to fetch users asynchronously
task = fetch_users.delay()
# Return a task ID to track the progress
return jsonify({"task_id": task.id}), 202
# Endpoint to retrieve the result of the task
@app.route('/users/<task_id>', methods=['GET'])
def get_users_task_result(task_id):
task = fetch_users.AsyncResult(task_id)
if task.state == 'SUCCESS':
return jsonify(task.result)
else:
return jsonify({"message": "Task is still processing"}), 202
if __name__ == '__main__':
# Create the database tables if they don't exist
Base.metadata.create_all(engine)
app.run(debug=True)Run multiple tasks
Imagine you have an application that needs to perform multiple independent tasks, such as sending emails, generating reports, and updating user profiles, all triggered by a single API call. Celery shines in these scenarios by allowing you to run these tasks concurrently, thus speeding up the entire process.
Here’s a basic example of how you can implement this:
from celery import Celery
app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
@app.task
def send_email(user_id):
# Logic to send email
return f"Email sent to user {user_id}!"
@app.task
def generate_report(user_id):
# Logic to generate report
return f"Report generated for user {user_id}!"
@app.task
def update_profile(user_id):
# Logic to update user profile
return f"Profile updated for user {user_id}!"
# Example function to run multiple tasks
def handle_user_actions(user_id):
results = []
results.append(send_email.delay(user_id))
results.append(generate_report.delay(user_id))
results.append(update_profile.delay(user_id))
return results
# In your Flask or Django views, you can call handle_user_actions to run these tasks asynchronously.This is how we can define multiple tasks in Celery and trigger them asynchronously. The tasks will be executed concurrently by different worker processes, which can significantly reduce your API’s response time.
Background Validation of Data
Now, let’s discuss ensuring data integrity through background validation. For instance, after a user uploads a large dataset, you might need to validate it before it can be processed or analyzed. Running such validations in the background frees up your API to handle other requests and improves the overall user experience.
Here’s how you could set up such a process:
from celery import Celery
app = Celery('data_validation', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
@app.task
def validate_data(dataset_id):
# Placeholder for actual validation logic
valid = True # Imagine some validation logic here
if valid:
return f"Dataset {dataset_id} is valid."
else:
return f"Dataset {dataset_id} contains errors."
# Trigger this task from your API after a dataset is uploaded
def handle_data_upload(dataset_id):
# Asynchronously validate the data
result = validate_data.delay(dataset_id)
return resultIn this example, the `validate_data` task checks the validity of the uploaded dataset. This task is triggered right after the dataset is uploaded and runs in the background without holding up the server. You can monitor the progress of the validation through Celery’s task ID and, once completed, take appropriate actions based on the validation results.
Conclusion
We have been using Celery for more than two years here at Decentro, working on more than four projects and processing more than 4GB of data. I have been very happy with its stability and the ecosystem that has been built around It, which helps us introduce new features to our existing Celery deployments without many changes.
I would highly recommend budding developers use this in their projects to improve their background and multiprocessing capabilities.
P.S. We would use Celery in future projects to reduce task running times.
With that, we have come to the end of another immersive experience of the production world.
If you wish to read more such blogs, please check our website’s [Blogs] section. We have previously covered topics like JsPDF, Locust, and much more.

